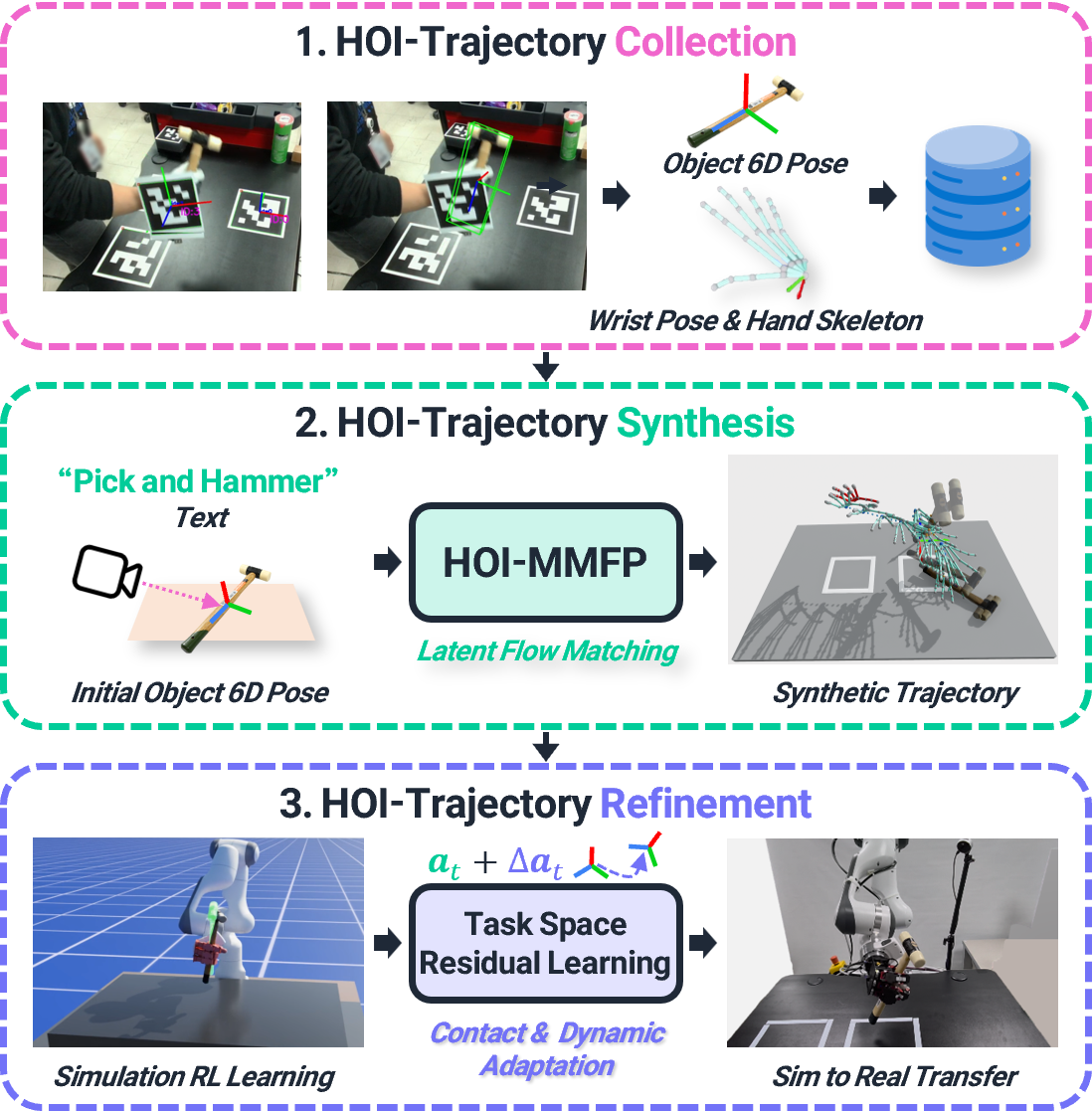
 DexSynRefine: Synthesizing and Refining Human-Object Interaction Motion for Physically Feasible Dexterous Robot Actions
DexSynRefine: Synthesizing and Refining Human-Object Interaction Motion for Physically Feasible Dexterous Robot Actions
TL;DR: Synthesizing sparse HOI motions and refining them into physically feasible dexterous robot actions via downstream task space residual RL.
Abstract
Learning dexterous manipulation from human-object interaction (HOI) data is a scalable alternative to teleoperation, but HOI demonstrations are sparse and provide only kinematic motion that is not directly executable under embodiment mismatch and contact-rich dynamics. We present DexSynRefine, a framework with three coupled components: HOI-MMFP, a task and object initial state-conditioned motion manifold primitives that synthesizes coordinated hand-object trajectories from sparse HOI demonstrations; a task-space residual RL policy that physically grounds the synthesized reference while inheriting its kinematic structure; and a contact-and-dynamics adaptation module that enables sim-to-real transfer from proprioceptive history. Across five dexterous manipulation tasks spanning pick-and-place, tool use, and object reorientation, our task-space residual policy outperforms prior action-representation baselines in simulations and transfers to a real robot on all five tasks, improving over kinematic retargeting by 50–70 percentage points.
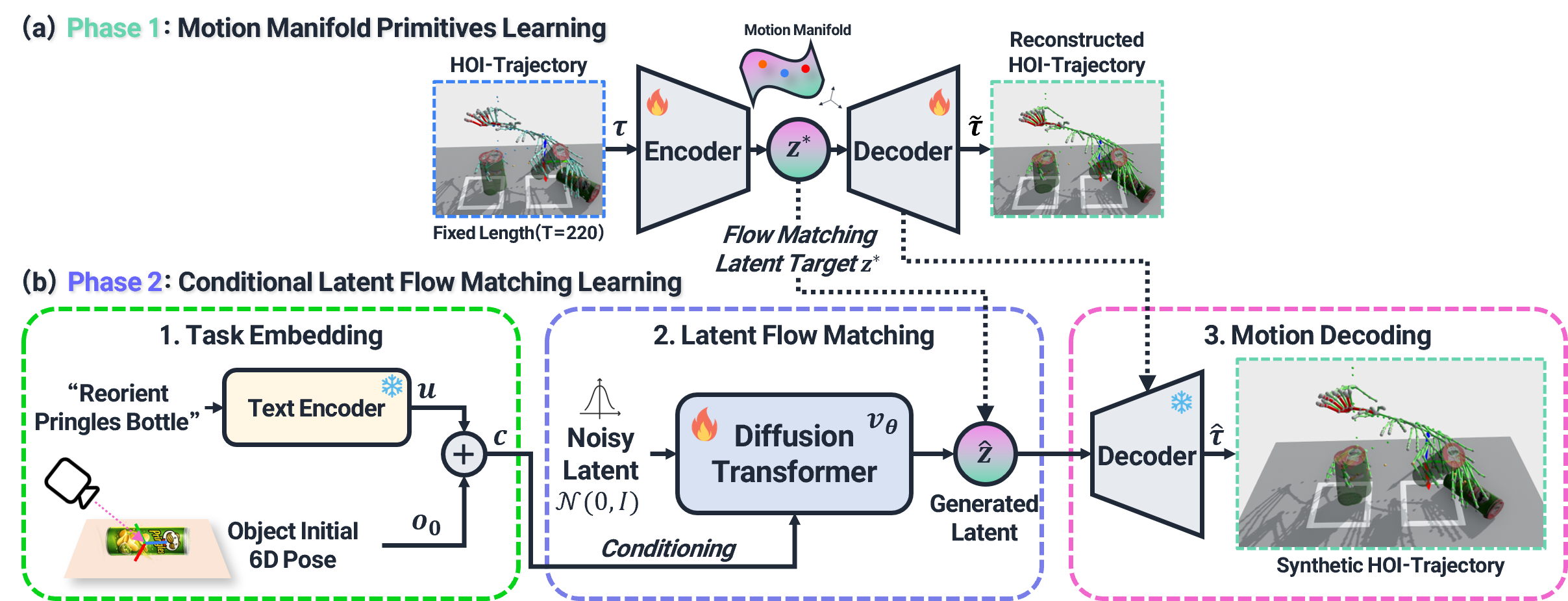
HOI-MMFP
HOI-MMFP is a task and object initial state-conditioned motion manifold primitives that synthesizes coordinated hand-object trajectories from sparse HOI demonstrations.
HOI Trajectory Synthesis Results
HOI-MMFP (Ours)
DiT-Full
TC-VAE
HOI-MMFP (Ours)
DiT-Full
TC-VAE
HOI-MMFP (Ours)
DiT-Full
TC-VAE
HOI-MMFP (Ours)
DiT-Full
TC-VAE
HOI-MMFP (Ours)
DiT-Full
TC-VAE
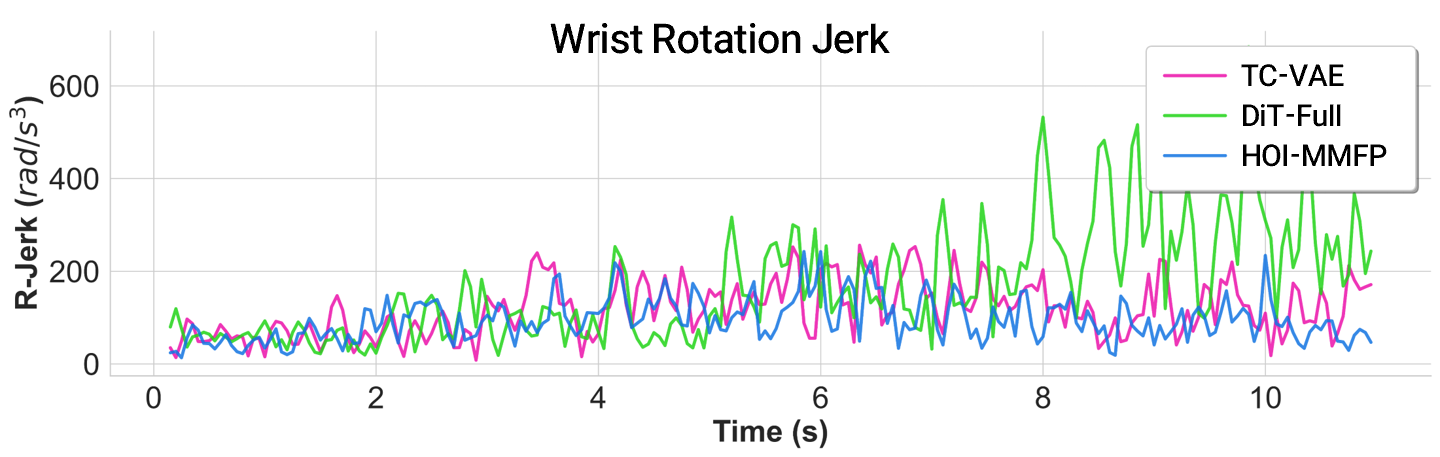
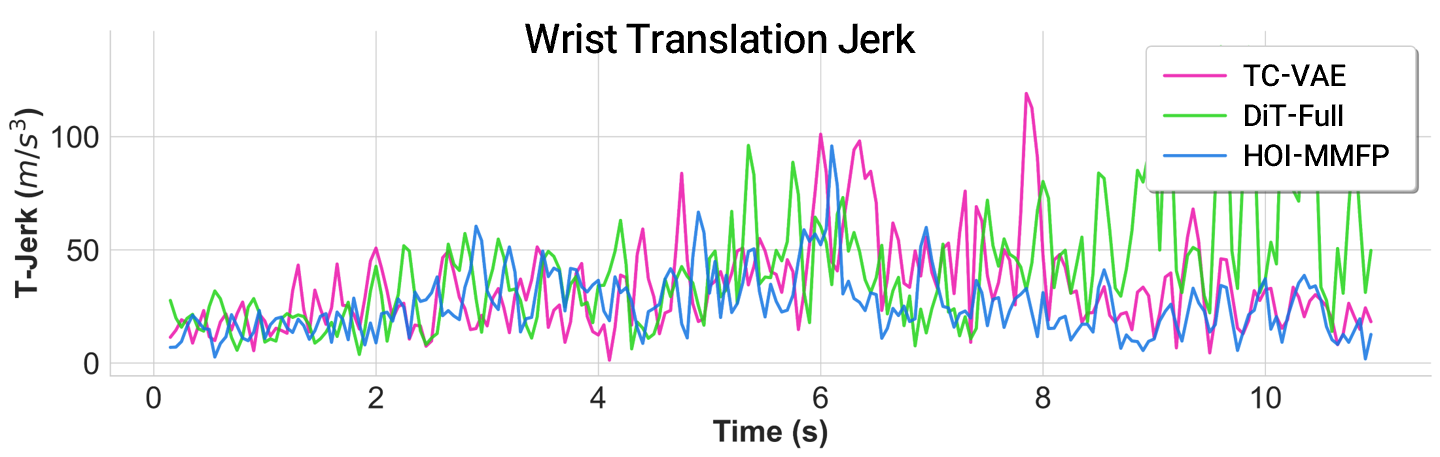
Synthesizing trajectories directly in trajectory space produces jittery and jerky motions, while our manifold-based synthesis yields smooth, physically plausible HOI trajectories.
Task Space Residual Action Learning
Our task-space residual RL policy physically grounds the synthesized reference motion while inheriting its kinematic structure, enabling robust execution under embodiment mismatch and contact-rich dynamics.
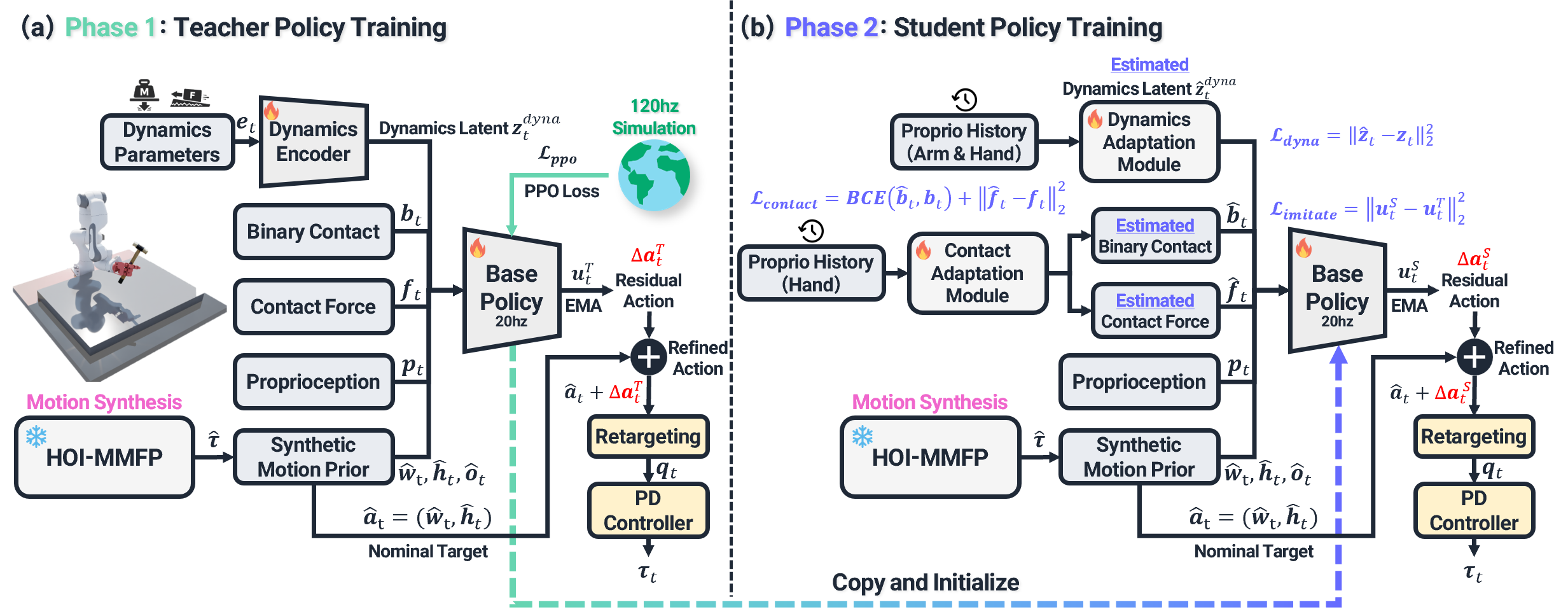
HOI Trajectory Refinement Results
Task Space Residual RL (Ours)
Kinematic Retargeting
Task Space Residual RL (Ours)
Kinematic Retargeting
Task Space Residual RL (Ours)
Kinematic Retargeting
Task Space Residual RL (Ours)
Kinematic Retargeting
Task Space Residual RL (Ours)
Kinematic Retargeting
Contact Adaptation Visualization
correct binary contact incorrect binary contact
GT: ground-truth contact Pr: predicted contact
Real World Deployment Results
Synthesized HOI Trajectory

Task Space Residual RL (Ours)
Kinematic Retargeting
Synthesized HOI Trajectory

Task Space Residual RL (Ours)
Kinematic Retargeting
Synthesized HOI Trajectory

Task Space Residual RL (Ours)
Kinematic Retargeting
Synthesized HOI Trajectory

Task Space Residual RL (Ours)
Kinematic Retargeting
Synthesized HOI Trajectory

Task Space Residual RL (Ours)
Kinematic Retargeting
Real World Digital Twin Visualization
Pick Up and Hammer
Synthesized Trajectory
Digital Twin Video
Reorient Pringles Bottle
Synthesized Trajectory

Digital Twin Video
BibTeX
coming soon